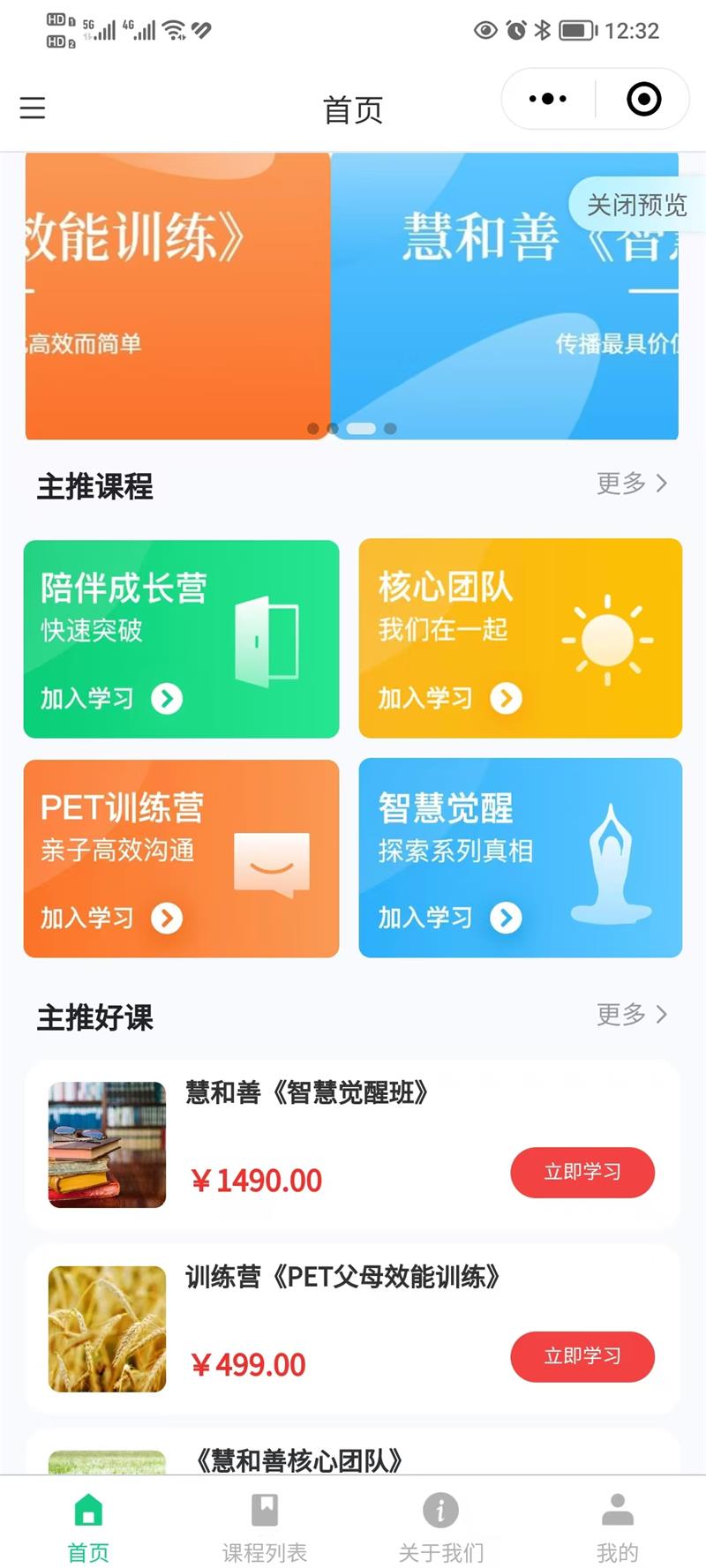
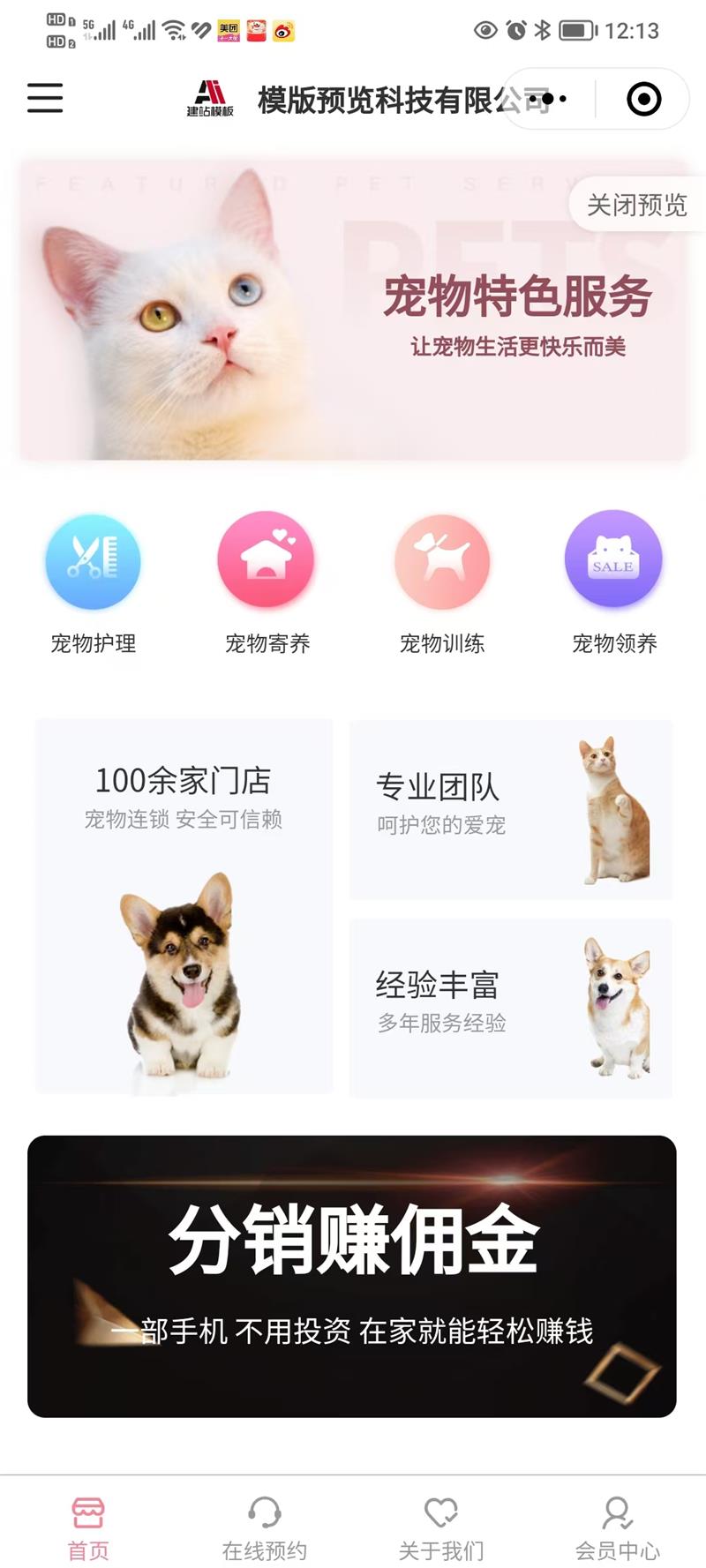
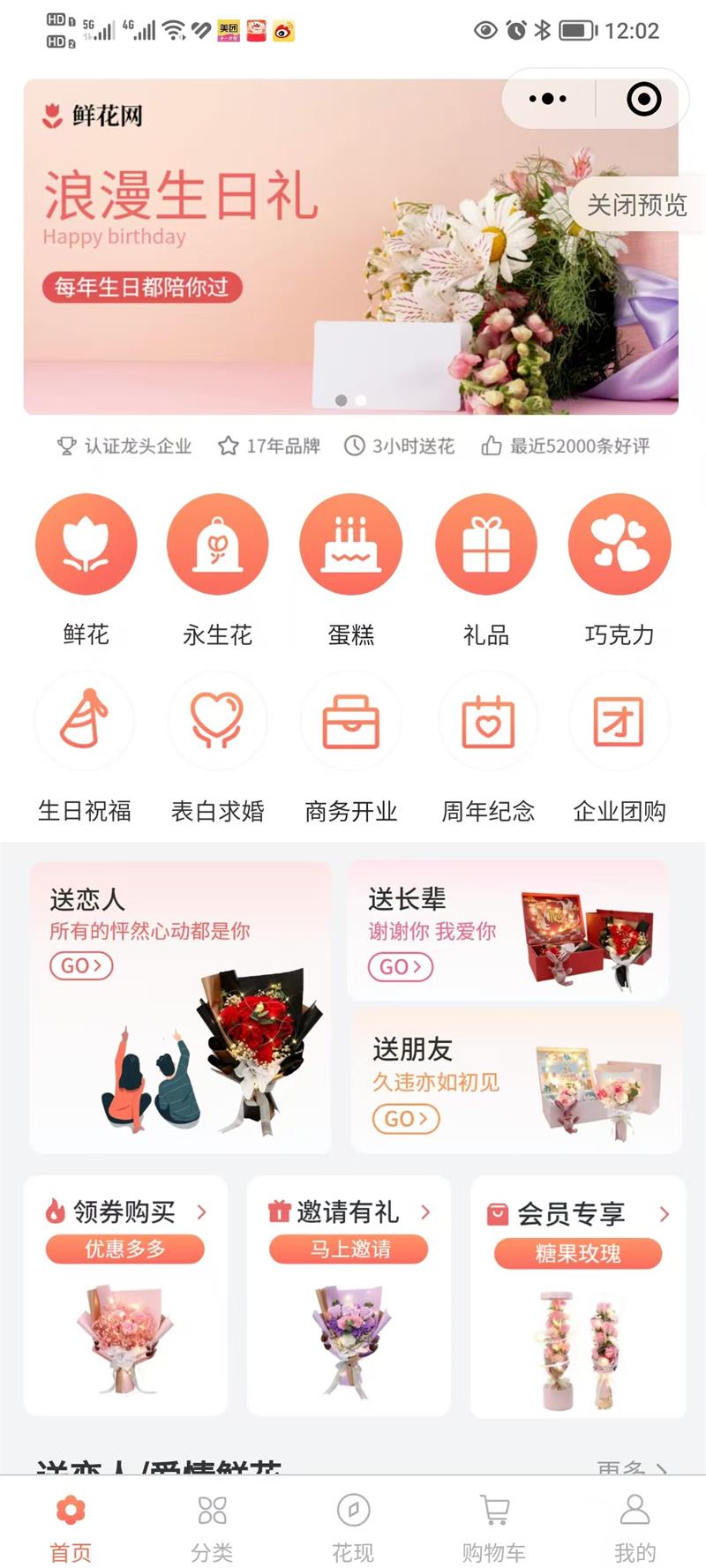
日期:2023-08-13访问量:0类型:小程序开发资讯
注意:[实现(雅可比)迭代可以使用 MPI 或 CUDA 实现。 想要使用CUDA的同学可以参考这里。
1.原理介绍【吃代码之前最好先了解原理】 1.1 公式介绍——可以忽略,这只是一个相关公式,推导过程可以忽略,但要注意最后标注的公式穿蓝色衣服
1.2 根据1.2得出的结论公式,我们可以知道如何计算
1.3 数据集划分
阐明:
MPI采用点对点模式实现雅可比并行计算,而不是一对多模式,因此需要将数据集划分为若干个等长的子数据集,每个进程负责处理一个数据单独设置,使进程与进程之间有一定程度的独立性;
您可以使用行分区或列分区

1.4 处理私有数据
注意,一旦使用了MPI,在程序启动的那一刻,你声明的每个变量、数组等都存在于每个进程中,并且变量名是相同的,所以当你使用MPI时,每个进程的数据矩阵的大小应该是总数据集的[维度/进程数,维度],但由于需要接收边界值,实际数组大小为[维度/进程数+2,维度+2]。
1.5 随机获取进程的执行轨迹
1.6
1.7 边界数据分布 1.8 通信过程 1.9 计算行号范围 2.1 1.0版本(比较容易理解,建议先看一下,虽然这个版本容易出现死锁,但下面有两个改进版本)
这里我就来说说为什么会出现死锁
如果有两个进程在处理数据集,但是他们都先执行接收操作而不是发送操作,那么这两个进程就会因为无法接收数据而一致等待,如果没有外部干预,他们就会永远等待
#include 2.2 无死锁版本2.0通用版使用指南【如果使用高级通用linux版本请阅读下文】
加载gcc(表示加载相应的模块,如果没有,请下载)
mpic++.cpp -o a.out
-np 16 ./a.out -N 256 -I 10000 (-np 16表示分配的处理器数量为16)
#include
#include
#include
#include
// determine the size of the array needing itering
#define N 100
// define the num of processes
#define X 4
// know the size of the array each process has
#define myarysize N / X
using namespace std;
int main(int argc, char* argv[])
{
int n, myid, numprocs ;
int up, down;
int opt;
int i, j;
// define the num of iterations
int nsteps = 1000;
char optstring[] = "N:I:"; // 分别代表-N, -I命令行参数,其中带:的表示参数可以指定值
double prev[myarysize + 2][N + 2], curr[myarysize + 2][N + 2], gather_arr[N][N + 2], temp[myarysize][N + 2];
MPI_Datatype onerow;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
// initialize all arrays
for (int i = 0; i < N; i++)
{
for (int j = 0; j < N + 2; j++)
{
if (i < myarysize)
temp[i][j] = 0;
gather_arr[i][j] = 0;
}
}
for (int i = 0; i < myarysize + 2; i++)
{
for (int j = 0; j < N + 2; j++)
{
prev[i][j] = 20.00;
}
}
if (myid == 0)
{
for (int j = 0; j < N + 2; j++)
{
// 将第一行的大约三分之一到三分之二之间的位置设置为100,其他设置为20
if (j > 0.3 * (N + 1) && j < 0.7 * (N + 1))
{
prev[0][j] = 100.00;
}
}
}
MPI_Type_contiguous(N + 2, MPI_DOUBLE, &onerow);
MPI_Type_commit(&onerow);
up = myid - 1;
if (up < 0) up = MPI_PROC_NULL;
down = myid + 1;
if (down > 3) down = MPI_PROC_NULL;
int begin_row = 1;
int end_row = myarysize;
for (n = 0; n < nsteps; n++)
{
MPI_Sendrecv(&prev[1][0], 1, onerow, up, 1000, &prev[myarysize + 1][0], 1, onerow, down, 1000, MPI_COMM_WORLD, &status);
MPI_Sendrecv(&prev[myarysize][0], 1, onerow, down, 1000, &prev[0][0], 1, onerow, up, 1000, MPI_COMM_WORLD, &status);
for (i = begin_row; i <= end_row; i++)
{
for (j = 1; j < N + 1; j++)
{
curr[i][j] = (prev[i][j + 1] + prev[i][j - 1] + prev[i - 1][j] + prev[i + 1][j]) * 0.25;
}
}
for (i = begin_row; i <= end_row; i++)
{
for (j = 1; j < N + 1; j++)
{
prev[i][j] = curr[i][j];
}
}
}/* 迭代结束*/
// 用一个临时数组存放这些更新完的数组(去掉首行和末行,因为这两行是边界)
for (int i = begin_row; i <= end_row; i++)
{
for (int j = 0; j < N + 2; j++)
{
temp[i - 1][j] = prev[i][j];
}
}
MPI_Barrier(MPI_COMM_WORLD);
//std::cout << "进程号为"< 0.3 * (N + 1) && i < 0.7 * (N + 1))
myfile << "100" << ", ";
else
myfile << "20" << ", ";
}
else if (p == N + 1)
myfile << "20" << ", ";
else
{
out << gather_arr[p - 1][i];
std::string str = out.str(); //从流中取出字符串 数值现在存储在str中,等待格式化。
myfile << str << ", ";
}
}
myfile << "\n";
}
myfile.close();
}
return 1;
}
2.3 高级版本3.0【带输出时间】,同时采用命令行参数的形式来确定进程数、矩阵维数、迭代次数。 可以看到改进版中我把对应的数组从静态数组改成了动态数组。 数组,这是因为静态数组不允许初始值为变量,只能是常量,但是从命令行获取迭代次数和矩阵维数时,只能传入动态变量改进版中,可以看到使用函数时,使用了两个一维数组,这里必须是一维的,因为一维数组中的地址空间是连续的,所以方便收集起来,二维的就不一定了。 linux下如何使用
-np 16 ./a.out -N 256 -I 10000 (-np 16 表示处理器数,也表示进程数,-N 256 表示矩阵维度为256,-I 10000 表示矩阵维数为256迭代次数为 10000)
#include TAG标签:解方程小程序
日期:2023-08-13 浏览量:62
日期:2023-08-12 浏览量:106